Machine Learning is broadly categorized under the following headings:
Machine learning evolved from left to right as shown in the above diagram.
Initially, researchers started out with Supervised Learning. This is the case of housing price prediction discussed earlier.
This was followed by unsupervised learning, where the machine is made to learn on its own without any supervision.
Scientists discovered further that it may be a good idea to reward the machine when it does the job the expected way and there came the Reinforcement Learning.
Very soon, the data that is available these days has become so humongous that the conventional techniques developed so far failed to analyze the big data and provide us the predictions.
Thus, came the deep learning where the human brain is simulated in the Artificial Neural Networks (ANN) created in our binary computers.
The machine now learns on its own using the high computing power and huge memory resources that are available today.
It is now observed that Deep Learning has solved many of the previously unsolvable problems.
The technique is now further advanced by giving incentives to Deep Learning networks as awards and there finally comes Deep Reinforcement Learning.
Let us now study each of these categories in more detail.
Supervised Learning
Supervised learning is analogous to training a child to walk. You will hold the child’s hand, show him how to take his foot forward, walk yourself for a demonstration, and so on until the child learns to walk on his own.
Regression
Similarly, in the case of supervised learning, you give concrete known examples to the computer. You say that for given feature value x1 the output is y1, for x2 it is y2, for x3 it is y3, and so on.
Based on this data, you let the computer figure out an empirical relationship between x and y.
Once the machine is trained in this way with a sufficient number of data points, now you would ask the machine to predict Y for a given X. Assuming that you know the real value of Y for this given X, you will be able to deduce whether the machine’s prediction is correct. Thus, you will test whether the machine has learned by using the known test data.
Once you are satisfied that the machine is able to do the predictions with a desired level of accuracy (say 80 to 90%) you can stop further training the machine. Now, you can safely use the machine to do the predictions on unknown data points, or ask the machine to predict Y for a given X for which you do not know the real value of Y. This training comes under the regression that we talked about earlier.
Classification
You may also use machine learning techniques for classification problems. In classification problems, you classify objects of similar nature into a single group.
For example, in a set of 100 students say, you may like to group them into three groups based on their heights — short, medium, and long. Measuring the height of each student, you will place them in a proper group. Now, when a new student comes in, you will put him in an appropriate group by measuring his height.
By following the principles in regression training, you will train the machine to classify a student based on his feature — the height. When the machine learns how the groups are formed, it will be able to classify any unknown new student correctly.
Once again, you would use the test data to verify that the machine has learned your technique of classification before putting the developed model in production.
Supervised Learning is where AI really began its journey. This technique was applied successfully in several cases. You have used this model while doing the hand-written recognition on your machine.
Several algorithms have been developed for supervised learning. You will learn about them in the following chapters.
Unsupervised Learning
In unsupervised learning, we do not specify a target variable to the machine, rather we ask the machine “What can you tell me about X?”. More specifically, we may ask questions such as given a huge data set X, “What are the five best groups we can make out of X?” or “What features occur together most frequently in X?”. To arrive at the answers to such questions, you can understand that the number of data points that the machine would require to deduce a strategy would be very large.
In the case of supervised learning, the machine can be trained with even about a few thousand data points. However, in the case of unsupervised learning, the number of data points that are reasonably acceptable for learning starts in a few million. These days, the data is generally abundantly available. The data ideally requires curating. However, the amount of data that is continuously flowing in a social area network, in most cases data curation is an impossible task.
The following figure shows the boundary between the yellow and red dots as determined by unsupervised machine learning. You can see clearly that the machine would be able to determine the class of each of the black dots with fairly good accuracy.
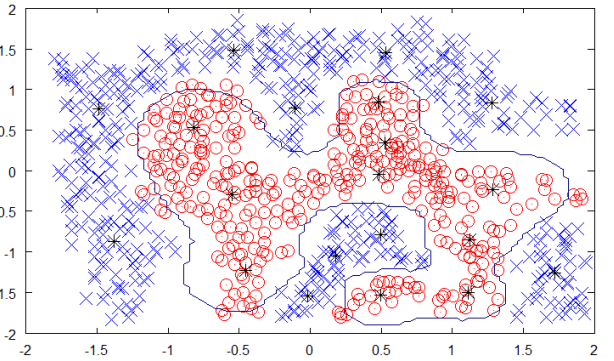
Source:https://chrisjmccormick.files.wordpress.com/2013/08/approx_decision_boun dary.png
Unsupervised learning has shown great success in many modern AI applications, such as face detection, object detection, and so on.
Reinforcement
Learning Consider training a pet dog, we train our pet to bring a ball to us. We throw the ball at a certain distance and ask the dog to fetch it back to us. Every time the dog does this right, we reward the dog. Slowly, the dog learns that doing the job rightly gives him a reward and then the dog starts doing the job the right way every time in future.
Exactly, this concept is applied in “Reinforcement” type of learning. The technique was initially developed for machines to play games. The machine is given an algorithm to analyze all possible moves at each stage of the game. The machine may select one of the moves at random.
If the move is right, the machine is rewarded, otherwise, it may be penalized. Slowly, the machine will start differentiating between right and wrong moves and after several iterations would learn to solve the game puzzle with better accuracy. The accuracy of winning the game would improve as the machine plays more and more games.
The entire process may be depicted in the following diagram:
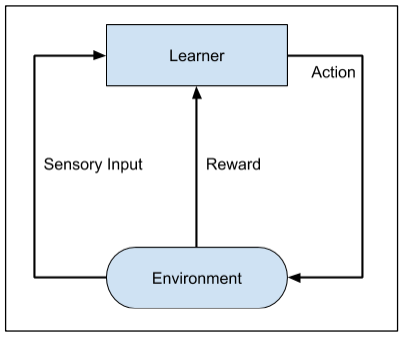
This technique of machine learning differs from supervised learning in that you need not supply the labeled input/output pairs. The focus is on finding the balance between exploring the new solutions versus exploiting the learning solutions.
Deep Learning
Deep learning is a model based on Artificial Neural Networks (ANN), more specifically Convolutional Neural Networks (CNN)s. There are several architectures used in deep learning such as deep neural networks, deep belief networks, recurrent neural networks, and convolutional neural networks.
These networks have been successfully applied in solving the problems of computer vision, speech recognition, natural language processing, bioinformatics, drug design, medical image analysis, and games. There are several other fields in which deep learning is proactively applied.
Deep learning requires huge processing power and humongous data, which is generally easily available these days. We will talk about deep learning more in detail in the coming chapters.
Deep Reinforcement Learning
Deep Reinforcement Learning (DRL) combines the techniques of both deep and reinforcement learning. The reinforcement learning algorithms like Q-learning are now combined with deep learning to create a powerful DRL model.
The technique has been with great success in the fields of robotics, video games, finance, and healthcare. Many previously unsolvable problems are now solved by creating DRL models. There is lots of research going on in this area and this is very actively pursued by the industries.
So far, you have got a brief introduction to various machine learning models, now let us explore slightly deeper into various algorithms that are available under these models.
Comments
Post a Comment